MDIM Journal of Management Review and Practice

 Search
Search

Abhijit Pandit1 and Trinankur Dey2
and Trinankur Dey2
1 Management Development Institute Murshidabad, Kolkata, West Bengal, India
2 Faculty of Management and Commerce, The ICFAI University Tripura, Kamalghat, Tripura, India

Creative Commons Non Commercial CC BY-NC: This article is distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 License (http://www.creativecommons.org/licenses/by-nc/4.0/) which permits non-Commercial use, reproduction and distribution of the work without further permission provided the original work is attributed.
Modern networking conversations generate annotated metadata, necessitating a method for synthesizing insights from statistics. Emotion detection is crucial for practical conversations, distinguishing joy, grief, and wrath. Corpora are becoming the standard for human–machine interaction, aiming to make interactions feel natural and real. A paradigm that identifies debates and customer views can provide a human touch to these interactions. Researchers developed a machine learning framework for assessing emotions in English phrases, utilizing Long Short Term Memory perspective and real-time emotion recognition in idiomatic speech. Emotion recognition rule is created using ontologies like Word Net and Concept Net, Naive Bayes, and Random Forest. Real-time analysis of written words and facial expressions significantly outperforms current algorithms and commandment classifiers in identifying emotional states.
Feelings, detailed statistics, data mining, machine learning
Introduction
Social Impact
Emotion recognition challenges humans to comprehend emotions, requiring advanced machine learning techniques, and comprehensive data for robots to effectively respond. Emotion recognition challenges individuals’ perception and understanding, but humans can identify and express emotions (Zahra et al., 2009). To effectively respond to emotional cues, robots require statistical data and advanced machine learning techniques (Cohn & Katz, 1998). Advanced monitoring systems identify users’ thoughts and emotions through conversational formats (Liyanage et al., 2000). Wearable biosensors analyse emotions using web browsers and calendars. The evolution of monitoring systems has paved the way for the identification of users’ emotions across diverse communication formats, such as chat messages and social media interactions. While wearable devices can capture biomedical data, their practicality for day-to-day use is limited. In this context, the integration of soft biosensors into web browsers emerges as a novel approach, employing analyses of tools like calendars and social networks to infer users’ emotional states.
Text-based emotion recognition applications include detecting adverse emotions in email communications, improving query retrieval, and using emotional models like hourglass and Ekman’s categories. Understanding emotional keywords and contextual placement in text is essential for emotion detection (Kao et al., 2009). Practical applications of text-based emotion recognition extend to areas like identifying negative emotions in emails to safeguard employees’ well-being. Employing a search engine to categorize notes based on emotional states holds the potential to elevate user experiences and enhance the retrieval of relevant queries. Emotion identification systems rely on established models like the hourglass model and Ekman's emotion categories. The precise comprehension of emotional keywords and their contextual positioning within text becomes pivotal for achieving accurate emotion detection. Even emotion recognition encompasses the analysis of facial expressions and textual content. Emotion recognition involves analysing facial expressions and textual content. Advances in facial expression detection and comprehension enable automated systems to accurately perceive and respond to human emotions (Calvo & D’Mello, 2010). Leveraging computer vision and artificial intelligence techniques, algorithms, and statistical methods are employed to recognize facial expressions.
Figure 1 score is crucial in machine learning for assessing classification models’ performance in imbalanced datasets. This study aims to identify emotions from neutral to intense sentiments, contributing to emotion recognition and societal implications.
Emotion classification uses keyword-based, machine learning, and hybrid methods to improve accuracy and impact society by systematically categorizing emotional keywords using tools like WordNet-Affect.
Nonetheless, the exclusive reliance on keywords encounters drawbacks tied to context and ambiguity, which have implications for understanding emotions in various contexts. Machine learning strategies, on the other hand, leverage trained models to achieve precise emotion recognition, with a particular emphasis on understanding the context within sentences.
The integration of semantic labels and sentence features presents innovative yet intricate techniques with potential social implications. Techniques such as mutual action histograms offer promise in identifying heightened emotional states in text, which could impact how emotions are interpreted and understood in online conversations.
Figure 1. Workflow Diagrams for Expressing Emotions via Text.

Hybrid approaches combining Support Vector Machines (SVM), Naive Bayesian, and Max Entropy introduce opportunities to elevate the accuracy of emotion classification, which in turn could benefit applications across social interactions. Hierarchical taxonomy systems and rule-based morphological systems contribute to refining the accuracy of these methods, potentially influencing how emotions are detected and interpreted in various forms of communication.
Review of Literature
The challenges inherent in emotion recognition prompt a diverse exploration of methods, a pursuit that can contribute to understanding and improving emotional interpretation in digital communication. The incorporation of recurrent neural networks and distributional semantic models introduces potential avenues to further advance emotion recognition techniques, with possible implications for how emotions are comprehended and engaged with across various societal contexts.
Bibliometric Coupling
Bibliometric coupling is a technique employed in bibliometrics and scientometrics to build a relationship between scientific articles based on the number of references they have in common. This methodology facilitates the identification and visualization of the cognitive framework of study domains, groups of interconnected documents, and developing patterns in scientific literature.
Coupling Strength refers to the degree of interdependence or connection between two or more entities. It measures the extent to which changes in one entity affect or influence the behavior of another entity. The degree of coupling between two papers is measured by the number of references they share. A higher coupling strength implies a stronger correlation between the texts, indicating that they are operating within the same scientific topic or subfield.
Visualization of a Network
Documents are depicted as nodes inside a network. The edges, which are lines connecting the nodes, show the degree of connectivity between them. The thickness of the edges can indicate the level of coupling strength, with thicker lines representing stronger connections.
Groupings
Nodes (documents) that have a strong correlation tend to group together in clusters.
Every cluster has the ability to represent a distinct topic, theme, or study area within the wider field. Clusters can be differentiated by utilizing various colors.
Image Analysis
The graphic depicts a network of papers that is formed by bibliometric coupling. Below is a comprehensive analysis of the various elements: Nodes (sometimes known as bubbles):
The magnitude of the bubble frequently signifies the number of citations that document has garnered, with larger bubbles denoting articles that have earned a greater number of citations.
Designations
The labels on the bubbles commonly display the author(s) and the year of publication. For example, the term “chou (2020)” denotes a scholarly article authored by Chou and published in the year 2020.
Color Spectrum
Distinct hues are employed to indicate separate clusters. For instance, the green bubbles could symbolize a distinct field of research, while the blue bubbles indicate a different field. Edges, often known as lines, are one-dimensional geometric figures that extend infinitely in both directions.
The lines connecting the bubbles indicate bibliometric connection. The quantity and width of these lines signify the intensity of the relationship. Increased line density or increased line thickness between two bubbles indicates a greater number of shared references. Research significance is in its ability to identify and analyse current trends in the field. Bibliometric coupling enables academics to discern prevailing patterns and popular subjects within a particular domain. Through the analysis of clusters (Figure 2), one can discern the predominant focus of attention and identify developing areas of interest.
Figure 2. Bibliometric Coupling was Performed on Available Literature with the Help of Dimensions and VOSviewer.

Source: Created with the help of Dimensions and VOSviewer.
Knowledge Domain Mapping
It offers a graphical depiction of the interconnections between various scientific subjects. Researchers are able to gain insight into how their study aligns with the wider scope of their area.
Cooperation and Establishment of Professional Connections
This approach might additionally emphasize possible partners by displaying the researchers who are engaged in comparable subjects.
Strategic Planning
Institutions and funding bodies can utilize bibliometric coupling to pinpoint crucial areas for investment and support. It aids in making well-informed decisions regarding the prioritization of research fields.
Analysis of the Image: Prominent Clusters
The red cluster, featuring distinguished writers such as Chou et al. (2020) and Singh et al. (2021), signifies a firmly established field of research with notable interrelationships. Smaller clusters or isolated nodes may indicate nascent areas of research that are currently in the process of development. Chou et al. (2020) is represented by larger bubbles, indicating that these articles have received a high number of citations, reflecting their significant influence within their respective study field. Interdisciplinary study or the convergence of multiple fields is indicated by the connection of clusters of different colors in specific locations. Through the examination of bibliometric coupling, researchers can acquire a more profound comprehension of the organization and fluctuations of scientific knowledge, enabling them to navigate the extensive body of literature with greater efficiency.
The surge in sentiment analysis's popularity and its impact on human–computer interaction has spurred researchers to confront the issue. Cognitive neuroscience, delving into the brain–mind connection, underscores the insufficiency of solely relying on logic for decision-making.
In response to this challenge, researchers have embraced sophisticated methods such as bidirectional long short-term memory for training models. The refinement of the initial training phase and enhancement of model accuracy are achieved through hyperparameter tuning. Additionally, preprocessing procedures play a role in augmenting model performance.
Methodology
The researchers utilized libraries for text and facial expression analysis, imported classifiers, and performed algorithm evaluation using test train split. Random Forest and Naive Bayes algorithms were implemented, and a classification report was obtained. The neural network model processed input images for real-time emotion prediction.
The output of this code, depicted in Figure 3, demonstrates the prediction of human emotions utilising a deep learning model in Python.
SVM is a supervised machine-learning algorithm effective in binary and multiclass classification tasks. It finds an optimal hyperplane to separate data points of different classes in a multidimensional space, with support vectors playing a vital role. SVM uses the kernel trick for nonlinear data and allows for soft margin classification. It has advantages in handling high-dimensional data and robustness against overfitting. However, SVM can be computationally expensive for large datasets, and tuning the kernel and penalty parameter C is essential for optimal performance. Overall, SVM is widely used in machine learning for binary classification tasks.
Results and Implications
To display human emotions in pictures using Python, you can use facial expression recognition libraries and tools. One popular library for this purpose is OpenCV, which provides functionalities for face detection and facial expression recognition. Additionally, you can use pretrained deep learning models for emotion recognition, such as those available in the TensorFlow or PyTorch ecosystems. Here’s a simple example using OpenCV for facial expression recognition:
Figure 3. Prediction of Human Emotions Using Deep Learning Model and Python.

import numpy as np
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Step 1: Load and preprocess the dataset
# Assuming you have features (X) and corresponding emotion labels (y)
# Step 2: Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# Step 3: Choose and train the machine learning model (e.g., SVM)
model = SVC(kernel = ‘linear’)
model.fit(X_train, y_train)
pip install opencv-python
pip install numpy
import cv2
import numpy as np
# Load pre-trained Haar Cascade classifier for face detection
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + ‘haarcascade_frontalface_default.xml’)
# Load pre-trained deep learning model for emotion recognition
emotion_model = cv2.dnn.readNetFromTensorflow(“path/to/your/emotion_model.pb”)
# Define emotion labels
emotion_labels = {0: ‘Angry’, 1: ‘Disgust’, 2: ‘Fear’, 3: ‘Happy’, 4: ‘Neutral’, 5: ‘Sad’, 6: ‘Surprise’}
# Load the input image
image_path = “path/to/your/image.jpg”
image = cv2.imread(image_path)
# Convert the image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Detect faces in the image
faces = face_cascade.detectMultiScale(gray_image, scaleFactor = 1.1, minNeighbors = 5, minSize = (30, 30))
# Process each detected face
for (x, y, w, h) in faces:
face_roi = gray_image[y:y + h, x:x + w]
face_roi = cv2.resize(face_roi, (48, 48))
face_roi = face_roi.astype(“float”) / 255.0
face_roi = np.expand_dims(face_roi, axis = 0)
face_roi = np.expand_dims(face_roi, axis = -1)
# Predict the emotion
emotion_preds = emotion_model.predict(face_roi)[0]
emotion_label = emotion_labels[np.argmax(emotion_preds)]
Figure 4. Prediction ii of Human Emotions Using Deep Learning Model and Python.
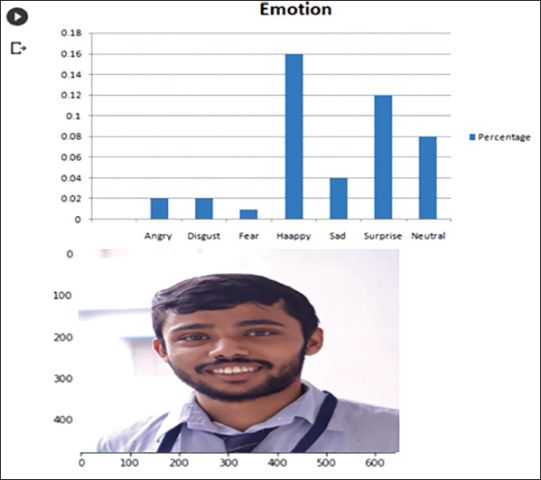
# Draw a rectangle around the face and display the emotion label
cv2. rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2. put Text (image, emotion_label, (x, y - 10), cv2. FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
In this code, one needs to replace “path/to/your/emotion_model.pb” with the actual path to pretrained deep learning model for emotion recognition. The model should be trained to recognize emotions like Angry, Disgust, Fear, Happy, Neutral, Sad, and Surprise.
Figure 4 illustrates the model’s capacity to forecast human emotions, highlighting its practical utility.
To maximize the positive impact of machine learning on human emotions, human-cantered design, ethical considerations, and inclusivity must be prioritized, involving collaboration between technologists, healthcare professionals, and users themselves.
Conclusion
In summary, there are a lot of potential and obstacles in the subject of emotion recognition when it comes to teaching robots to understand and react to human emotions. Robust datasets and sophisticated machine-learning algorithms are needed for this. Humans are naturally able to recognize and communicate their emotions (Zahra et al., 2009); however, robots find it difficult to effectively understand these signs and must instead rely on statistical data and complex algorithms (Cohn & Katz, 1998). According to De Silva and Ng (2000), the development of monitoring systems has made room for novel methods of identifying emotions, such as the combination of web-based resources with wearable biosensors. However, wearable technology is still not very useful for everyday tasks, which makes soft biosensors incorporated into online settings a viable substitute for inferring. Text-based emotion identification has several real-world uses, such as enhancing query retrieval systems and identifying negative emotions in emails to protect worker welfare. Emotional keywords and their contextual location must be understood in order to accurately identify emotions in text. This may be done by using models such as the hourglass and Ekman's emotion categories (Kao et al., 2009). Artificial intelligence and computer vision developments have expanded automated systems’ capacity to interpret text and facial expressions (Calvo & D’Mello, 2010). Such systems use difficult algorithms, as well as statistical techniques; thus, boosting the identification of emotions. Emotion recognition technologies, facial expression analysis, as well as text analysis, provide new opportunities in increasing human–computer interaction and understanding the dynamics of emotions that engulf various communication channels. OpenCV and TensorFlow or PyTorch libraries allow demonstrating their practical usability in the case of facial expression detection and deep learning models, which affect social interaction and the field of artificial intelligence.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, or publication of this article.
Funding
The authors received no financial support for the research, authorship, or publication of this article.
ORCID iDs
Abhijit Pandit https://orcid.org/0000-0003-2122-3468
Trinankur Dey https://orcid.org/0000-0002-1119-2496
Calvo, R. A., & D’Mello, S. (2010). Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Transactions on Affective Computing, 1(1), 18–37. https://doi.org/10.1109/t-affc.2010.1
Chou, S. T., Lee, Z. J., Lee, C. Y., Ma, W. P., Ye, F., & Chen, Z. (2020). A hybrid system for imbalanced data mining. Microsystem Technologies, 26(9), 3043–3047.
Cohn, J. F., & Katz, G. S. (1998). Bimodal expression of emotion by face and voice. In Proceedings of the sixth ACM international conference on Multimedia: Face/gesture recognition and their applications (pp. 41–44). Association for Computing Machinery. https://doi.org/10.1145/306668.306683
De Silva, L., & Ng, N. P.C. (2002). Bimodal emotion recognition. In Proceedings fourth IEEE international conference on automatic face and gesture recognition. IEEE. https://doi.org/10.1109/afgr.2000.840655
Kao, E. C. C., Liu, C. C., Yang, T. H., Hsieh, C. T., & Soo, V. W. (2009). Towards text-based emotion detection a survey and possible improvements. In Proceedings of the 2009 international conference on information management and engineering. IEEE. https://doi.org/10.1109/icime.2009.113.
Khalili, Z., & Moradi, M. H. (2009). Emotion recognition system using brain and peripheral signals: Using correlation dimension to improve the results of EEG. In Proceeding of the 2009 international joint conference on neural networks (pp. 1920–1924). IEEE.
Liyanage, L., Elhag, T., Ballal, T., & Li, Q. (2000). Knowledge communication and translation – A knowledge transfer model. Journal of Information & Knowledge Management, 8(1), 31–42.
Singh, J., Aggarwal, S., & Verma, A. (2021). Application based categorization of datasets for implementing data mining techniques. In Proceedings of the 2021 2nd global conference for advancement in technology (GCAT) (pp. 1–7). IEEE.
Zahra, S. A., Gedajlovic, E., Neubaum, D. O., & Shulman, J. M. (2009). A typology of social entrepreneurs: Motives, search processes, and ethical challenges. Journal of Business Venturing, 24(5), 519–532.
